前言
最近爬网站视频的时候发现视频都是用m3u8的格式,不能直接下载
百度借鉴了一下下载方法后,就写了一个适合自己的方法
思路
m3u8 文件实质是一个播放列表(playlist),了解这个之后下载就比较简单了。
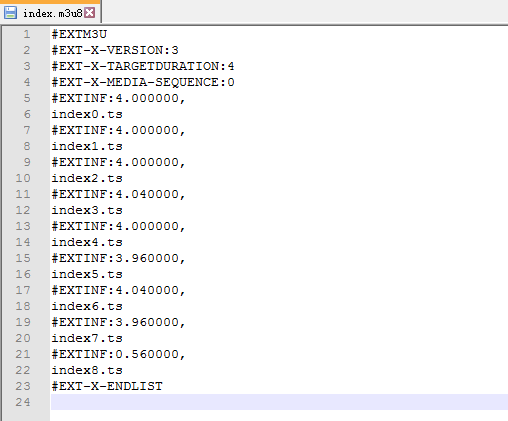
只需要把列表一个一个合并成url,就可以全部下载,再合并成一个视频
前提是这个m3u8没有加密,加密什么的太烦了!
代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
| import requests
import os
import time
def get_ts_urls(m3u8_index):
m3u8_urls = []
m3u8s = requests.get(m3u8_index).text
m3u8s = m3u8s.strip()
m3u8s = m3u8s.split('\n')
for m3u8 in m3u8s:
if m3u8.find('#') == -1:
m3u8_server = url_m3u8_index.replace(url_m3u8_index.split('/')[-1], '')
m3u8_url = m3u8_server + m3u8
m3u8_urls.append(m3u8_url)
print(m3u8_urls)
return m3u8_urls
def down_m3u8(urls):
ts_names = []
for url in urls:
try:
res = requests.get(url).content
try:
os.mkdir('临时下载文件夹')
except:
pass
ts_name = '临时下载文件夹/' + url.split('/')[-1]
ts_names.append(ts_name)
with open(ts_name, 'wb') as f:
f.write(res)
print('开始下载{}'.format(ts_name))
except:
pass
t = time.strftime("%Y%m%d%H%M%S", time.localtime())
file_path = str(t) + '.ts'
with open(file_path, 'wb') as fl:
for i in ts_names:
fl.write(open(i, 'rb').read())
os.remove(i)
try:
os.rmdir('临时下载文件夹')
except:
pass
if __name__ == '__main__':
url_m3u8_index = 'https://v.jingruila.com/public/videos/60ef8b9e05097b2cfd6e9071/index.m3u8'
m3u8_urls = get_ts_urls(url_m3u8_index)
down_m3u8(m3u8_urls)
print('下载完成')
|
后记
这个方法只适合部分m3u8下载,因为它比较简陋。
本文有个福利哦,认真学习的同学就能发现。。。